|
Image: (click to enlarge!)

Neben ein paar Vorbereitungs- und Zwischenschritten bestand die eigentliche Aufgabe des Marathon-Clusters aus zwei Schritten |
|
Image: (click to enlarge!)
Neben ein paar Vorbereitungs- und Zwischenschritten bestand die eigentliche Aufgabe des Marathon-Clusters aus zwei Schritten |
Die insgesamt 4 Videobänder wurden anschliessend mittels eines Sony Betacam MAZ Gerätes und eines unter Windows 98 laufenden PCs mit einer Hauppage PVR mit Hardware MPEG Encoder Karte in einzelne MPEG-Sequenzen zerlegt. Jede Sequenz bestand aus 11 Minuten Filmmaterial bei 25 Frames pro Sekunde, einer Bildauflösung von 352x288 und einer Farbtiefe von 24 Bit, was zu einer durchschnittlichen Datenmenge von ca. 110 MB führte. Die einzelnen Sequenzen wurden dann mit FTP auf einem via 100MBit und Crossconnect-Kabel angeschlossenen Rechner unter RedHat Linux 7.1 übertragen. Dort wurden die einzelnen Sequenzen mit mkisofs und cdrecord auf jeweils eine eigene CD gebrannt.
Das vom Script "create_dir.pl" aufgerufene Programm "dumpmpeg" wurde für den Marathon-Cluster modifiziert, da es in seiner ursprünglichen Form nur Bilder im BMP-Format erzeugt, was jedoch zu zu grossen Einzelbildern geführt hätte, und darüberhinaus von der Software des zweiten Schritts nicht gelesen werden kann. Deshalb wurde der Quellcode des Open-Source Programms dumpmpeg so modifiziert, dass es nach dem Abspeichern von jeweils 250 Bildern (10 Sekunden Film) diese mittels der netpbm Tools von BMP nach JPEG konvertierte. Die Konvertierung durch die netpbm-Tools ist zeitaufwendig, jedoch standen dem auf den SDL- und smpeg-Bibliotheken basierte dumpmpeg keine Routinen zur Verfügung, die ein direktes Abspeichern als JPEG erlaubt hätten. Ein Wegoptimieren der fork()- und exec()-Aufrufe durch Code aus den netpbm-Tools viel leider dem Zeitdruck zum Opfer.
Die zweite Veränderung an dumpmpeg stellte das Verzeichnis dar, in dem das Programm die erzeugten Bilder ablegte. Anstatt alle Bild in einem Verzeichnis abzulegen wurde für jeweils 250 Bilder ein eigenes Verzeichnis angelegt, was die Zugriffszeiten noch verbesserte.
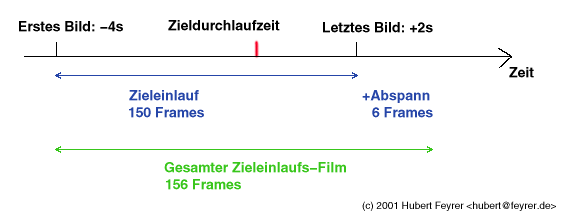
Ausgehend von der Zieldurchlaufzeit werden die Bilder des Zielvideos ermittelt |
Abschliessend kommen noch sechs Frames mit gleichem Inhalt, die ebenfalls in das Arbeitsverzeichnis kopiert werden. In eine vorgefertigten Maske mit den Logos der Sponsoren der Zieleinlaufsvideos wird mit Hilfe des Programms "convert" (Teil von ImageMagick) der Name des jeweiligen Läufers, seine Startnummer, die Zeit, Plazierung und die Disziplin geschrieben, damit diese am Ende des Zieleinlaufsfilms angezeigt werden.


Maske für den Abspann mit und ohne Daten |
Neben dem Zieleinlauf-Film wurde zusätzlich noch das Bild des exakten Zieleinlaufs gesichert, und wiederum mittels "convert" Name des Läufers, Zeit, Plazierung und Disziplin eingetragen.

Beispiel Zielfoto |
Das Zusammenrechnen des Films aus den einzelnen Bildern im temporären Verzeichnis wurde mit dem Programm mpeg_encode gemacht. Durch eine Parameterdatei wurde festgelegt wo das temporaere Verzeichnis war, welche Bilder daraus zu einem Film zusammengerechnet, und welche Client-Rechner diese Aufgabe übernehmen sollten. mpeg_encode startete dann auf jedem Client eine Berechnung für ein paar Bilder, um die Geschwindigkeit der einzelnen Knoten abschätzen zu können. Anschließend wurden dann die verbleibenden Bilder entsprechend auf die einzelnen Konten verteilt, die die Bilder dann via NFS lasen und die berechneten Teilfilme auch via NFS wieder an den Haupt-Prozess zurücklieferten, der die Teile dann vereinigte und das Ergebnis als eine MPEG-Datei ablegte. All dies führt das frei verfügbare Programm ohne jegliches Zutun automatisch aus, so dass hier sehr viel manuelle Arbeit (und mögliche Fehler) verhindert werden.
Die von mpeg_encode verwendete Parameterdatei lag für jeden der vier Subcluster vor, so dass die Ergebnisliste jeder Disziplin auf jedem Subcluster berechnet werden konnte - je nachdem wo gerade Rechenzeit frei war. Das Job-Scheduling wurde hier per Hand gemacht. Insgesamt existierten sechs Diszipline:
| Marathon-Damen: | 148 | Finisher |
| Marathon-Herren: | 1268 | Finisher |
| Halbmarathon-Damen: | 893 | Finisher |
| Halbmarathon-Herren: | 2469 | Finisher |
| Speedskating-Damen: | 202 | Finisher |
| Speedskating-Herren: | 521 | Finisher |
Die Ergebnislisten pro Disziplin lagen als CSV-Dateien vor, die durch ein perl-Script in ASCII-Dateien zerlegt wurden. Diese dienten dann wiederum dem perl-Script "mpeg250_pic.pl" als Eingabedatei. Für jeden Läufer wurden aus der Eingabedatei Name, Plazierung und v.a. die Zielzeit bekannt. Mit Hilfe der Bild-Datenbank war dann berechnet, innerhalb welcher Sequenz der Läufer lag, und es konnte das zugehörige Bild zum Zieldurchlauf errechnet werden. Dieses wiederum diente als Referenzpunkt für die 150 Bilder des Zieldurchlauf-Films, wie oben beschrieben. Nachdem die Bilder mitsamt des Abspanns im temporären Arbeitsverzeichnis abgelegt waren waren dann die Rechner des jeweiligen Clusters mit der Berechnung des MPEGs gefordert, und der Zielfilm wurde anschliessend zusammen mit dem Zielfoto in einem eigenen Verzeichnis Archiviert.
|
Image: (click to enlarge!)

Vom Job Control Rechner aus wurden die Subcluster mit den zu berechnenden Bildsequenzen versorgt, die auf dem NFS Server abgelegt waren. |
Das von "mpeg250_pic.pl" gestarteten mpeg_encode startete die Jobs auf den einzelnen (Sub)Cluster-Rechnern via rsh, um hier eine aufwendige Authentifizierung via ssh zu umgehen. Da das Zusammenrechnen eines einzelnen MPEGs zwischen 3 und 8 Sekunden dauerte wäre der Overhead der SSH-Authentifizierung, der in der Grössenordnung von ca. 2 Sekunden lag, zu sehr ins Gewicht gefallen, ohne irgend einen Vorteil zu bringen.
Abschliessend hier zwei Beispiel-Videos: Marathon Damen, Marathon Herren.